
背景
推荐系统在电商、短视频、新闻、广告等行业都有着广泛的应用。推荐系统能够比较准确理解终端用户的兴趣,提升终端用户的浏览体验。典型的工业界推荐系统一般采用多阶段漏斗的方式,通常包括召回、粗排、精排、重排等阶段,每个阶段要处理的商品数量是依次递减的,而对应的模型的参数量和计算复杂度通常是依次递增的。随着深度学习的发展,现在主流的推荐系统都是用深度学习模型来预估用户对于不同商品的偏好。深度学习大幅度提升了模型预估的准确度,并且能够支持多任务多场景的联合建模。但随之带来的问题是模型参数量和计算复杂度的大幅度增加,这给模型训练和在线推理服务都带来了巨大的挑战。为了提升模型的准确度,推荐模型通常需要在千亿规模的样本和特征上进行训练。即便采用分布式训练,训练一个推荐排序模型也要持续数天的时间。这给算法工程师探索和优化模型结构带来了巨大的压力。在线推理服务通常需要在有限的时间内返回结果(< 500ms),而现代推荐模型的巨大参数量和复杂的模型结构需要的计算量通常难以满足这样要求。
为了解决这些挑战,帮助用户更好的落地深度学习推荐算法,阿里云PAI团队研发了PAI-REC全链路解决方案,帮助用户以白盒化的方式快速构建推荐全链路的方案。如图1所示,PAI-REC平台包含了推荐全链路所需要的功能: 特征构建,模型训练,在线服务等。其中两个关键的功能是模型训练和模型推理,分别由EasyRec推荐算法框架和EasyRec Processor提供。 EasyRec推荐算法框架帮助用户快速训练推荐模型,其中提供了业界广泛使用的推荐算法模型,如DeepFM, DIN, DBMTL等,并支持通过组件化和自定义模型的方式快速构建新的模型结构,进一步还支持通过PAI-NNI-HPO做超参搜索。EasyRec算法框架的相关代码已经在github上开源。
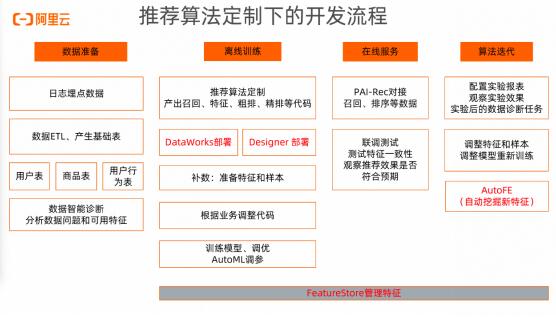
图1. PAI-REC推荐算法定制开发平台
PAI-REC在线推理链路如图2所示,其中EasyRec Processor负责模型推理环节。EasyRec Processor包含ItemFeatureCache, Feature Generator(特征交叉)和TF Model Serving三个部分,并能够从Kafka/OSS获取模型的增量更新,从FeatureStore获取特征的实时更新。
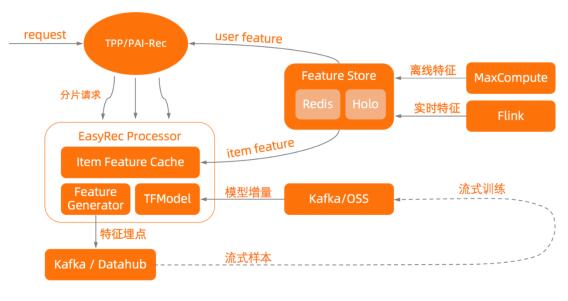
图2. PAI-REC在线推理链路
为了提升推荐模型训练和在线推理的效率,我们联合intel相关团队结合硬件的特性做了深入的优化,提升了模型训练的速度,同时提升了模型推理的QPS(每秒处理的请求次数),降低了模型推理的RT(响应时间),CPU的利用率也大幅度提升[20%->60%]。下面介绍一下EasyRec里面用到的一些优化方法。
AMX矩阵乘法优化
深度学习推荐模型里面通常会用到MLP和Attention等一般涉及到比较多的矩阵乘法计算,属于计算密集型,不仅影响算子内部的计算效率,也影响了算子调度的效率。OneDNN和MKL针对矩阵运算做了深度优化,提升了矩阵乘法的计算能力,但仍然受限于硬件的计算能力。为了进一步提升矩阵乘法的计算效率,可以选择使用英特尔® 第四代至强® 可扩展处理器Sapphire Rapids(SPR)来处理推荐系统的训练和推理。该处理器通过创新架构增加了每个时钟周期的指令,支持 8 通道 DDR5 内存,有效提升了内存带宽与速度,并通过PCIe 5.0实现了更高的 PCIe 带宽提升。该处理器不仅经过了一系列微架构的革新和技术规格的提升,还搭载了全新的AI加速引擎——英特尔®高级矩阵扩展(AMX)。
英特尔® AMX 技术与上一代深度学习加速技术——向量神经网络指令 VNNI及BF16相比,从一维向量演变为二维矩阵,因此能够充分利用计算资源,提高高速缓存的利用率,并且避免潜在的带宽瓶颈。这种改进显著提高了人工智能应用程序每个时钟周期的指令数,为AI工作负载中的训练和推理提供了显著的性能提升。
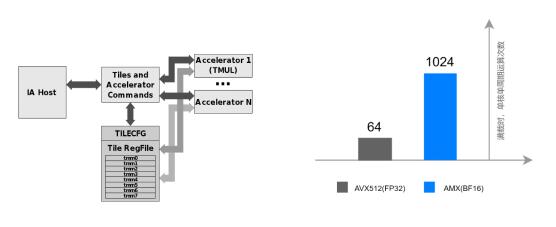
(a)AMX架构图 (b)单核单周期运算次数比较
图3.AMX架构和性能
图3a展示了英特尔® AMX的架构,其中包括了两个主要组成部分:(1)Tiles: 由八个二维寄存器组成(命名为 tmm0, tmm1, …, tmm7),每个寄存器的最大尺寸为16行,每行有512位,尺寸为1KiB。整个Tiles的大小为8KiB。
(2)TMUL: 它是与 Tile连接的加速引擎,可用于矩阵乘法计算执行。
AMX 支持INT8 和 BF16数据类型,用于 AI 工作负载中的矩阵乘法运算。如图3b所示,第四代英特尔® 至强® 可扩展处理器可在单位计算周期内可执行 1024 次 BF16 运算,与第三代英特尔® 至强® 可扩展处理器执行 FP32 运算的次数64 次相比,有16倍的性能提升。
混合精度运算
BFloat16浮点格式是一种计算机内存中占用16位的计算机数字格式。该格式是32位IEEE 754单精度浮点格式(float32)的截断(16位)版本。它保留了32位浮点数的近似动态范围。BFloat16用于降低存储需求,提高机器学习算法的计算速度。BFloat16是用于机器学习的自定义16位浮点格式,采用与IEEE 754标准相似的布局,但对于指数和尾数字段进行了修改,由一个符号位、八个指数位和七个尾数位组成。相比之下,IEEE 754标准的半精度浮点数(Float16)使用1位符号位,5位指数和10位尾数。IEEE 754标准的单精度浮点数(Float32)使用1位符号位,8位指数和23位尾数,因此BFloat16具有和Float32等效的动态范围。
BFloat16相比Float16的主要优势在于其更大的动态范围。由于具有更多的位数用于指数部分,BFloat16可以表示更大的数值范围和更小的数值间隔。这使得它在深度学习中具有一定的优势,因为在训练深度神经网络时,经常需要处理广泛的数值范围。另一个优势在于能够更快的与Float32进行相互转换,转换时只需要对最后16位进行填充或者移除即可实现快速转换。
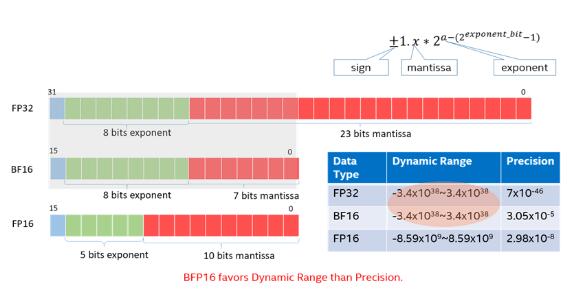
图4. BFloat16 浮点格式介绍
在该优化方案中,在Embedding部分及矩阵乘部分,用户可以选择使用BFloat16来进行相应的运算操作。经过测试,使用BFloat16可以在不损失精度的情况下,减少一半的内存。此外,使用框架原生的BFloat16到Float32的转换效率很低,在使用了AVX的硬件指令加速后,可大幅提高其性能。 进一步使用AMX可以提高BF16矩阵乘法的效率,使用AMX时处理器每个周期可以执行1,024次BFloat16(16位浮点数)操作。
算子融合和图优化
从图优化层面来看,算子融合通过将一系列算子融合成单个算子的方法,可有效提升性能。这是由于每个算子都需要一个Kernel启动,有时启动时间甚至会比实际的核心计算花费更多的时间。通过将一系列算子融合为一个单一的大算子,可以减少Kernel启动的开销。此外,算子融合还有助于提升CPU Cache的命中率,降低中间数据读取和写入内存的数据传输开销。
推荐模型除了DNN部分之外,另一个主要的部分是 embedding_lookup的计算. 这个功能在Tensorflow提供的实现有很多个算子来实现, 包括Unique, Gather, Reshape, ExpandDims, SparseSegmentSum等等几十个算子,如图4所示,计算效率非常低。在EasyRec里面我们将这些功能融合到一个算子里面执行,降低了算子调度的开销。进一步我们使用AVX指令优化embedding聚合(Combine)计算, 提升向量加法和乘法的计算效率。
为了降低部署的复杂度,针对常见的Embedding模型,我们设计了模板匹配算法,自动寻找和匹配embedding_lookup的子图,并将其替换成融合之后的算子, 使得用户现有模型,不需要经过任何调整,就能直接享受性能的上提升。embedding_lookup的前一步通常是string_to_hashbucket, bucketize, string_to_number等操作,如果能匹配到相应的OP,我们将其也融合到embedding_lookup的Op中,减少Kernel Launch的次数。优化之后,主流的推荐模型OP数量一般会减少一半以上,RT通常能降低50%以上。
(a) 优化前
(b) 优化后
图5. embedding_lookup子图优化案例
特征计算(FeatureGenerator)优化
推荐模型效果优化的一个关键的部分是关键特征的挖掘和构造。受限于反馈和特征稀疏的问题,推荐场景通常需要设计一些泛化性比较强的特征来提升模型的效果。其中泛化性比较好的一类特征是显示交叉特征,如LookupFeature, MatchFeature等。这类特征通过构建一个u2i的映射,记录用户在不同item上的行为的统计信息,如用户最近1小时在不同商品上的点击次数,在对应的类目上的点击次数等等。为了提高查找效率,这类信息在线通常以HashMap的形式存储。离线存储和传输考虑到数据分析和存储的效率,通常以字符串格式存储。从离线格式解析到HashMap的过程中字符串分割占用了比较多的计算量。为了加速字符串的解析,我们设计了一套新的StringSplit实现,如下图所示,通过AVX512向量化指令,批量处理输入的字符串字符,匹配分隔符,从而达到加速字符串的分割的目的。优化后的StringSplit实现实际测试速度是Tensorflow中原生的StringSplit实现速度的3倍。在读取CSV格式的数据训练进行训练的过程中,也涉及到比较多的字符串解析的工作,使用优化的StringSplitOp训练速度可以提升2倍以上。
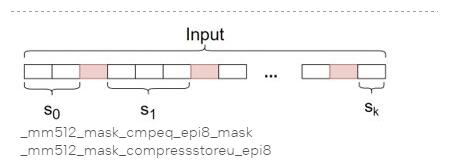
图6. StringSplit优化
为了实现特征计算和embedding_lookup的overlap执行,我们将特征计算的部分也封装成了Tensorflow的算子(Operation)。模型部署时,EasyRec Processor会根据特征配置自动构造特征计算的子图,并拼接到TFModel的graph里面,这个过程也是用户无序感知的。整合到同一个图里面之后,可以进一步开启grappler, xla, trt等图优化操作对整个大图做进一步的优化。
业务落地效果
上述的优化都已经沉淀到EasyRec训练框架和推理框架EasyRec Processor里面,并且在多个客户场景落地,帮助用户取得了显著的性能提升:
1.某电商场景精排模型,约2000 Feature Slots,模型参数20G,使用EasyRec Processor之后比原生的tf-serving qps提升了8倍,rt降低了70%;
2.某游戏场景精排模型,约500 Feature Slots,模型参数10G,使用EasyRec Processor之后比原生的tf-serving qps提升了4倍;
3.某游戏场景精排模型,在训练时采用了AMX优化,训练速度为优化前的2倍。
展望
采用第四代英特尔® 至强® 可扩展处理器来优化推荐系统性能,有助于降低部署专用加速器(如独立显卡)的成本,并更有效地控制推荐系统的总体拥有成本(TCO),从而使用户受益。为了提升更多深度学习模型的端到端性能,英特尔和阿里云正积极合作,探索创新方式来优化软硬件集成,加速深度学习模型的性能,使更多的云上用户获得收益。
此外,值得关注的是,英特尔于近期推出了第五代英特尔®至强® 可扩展处理器Emerald Rapids(EMR),该处理器同样搭载内置AI加速引擎AMX,相比上一代SPR提供多达3倍的LLC,单CPU支持8通道 5600MT/s DDR5。在2023年阿里云云栖大会上,阿里云ECS宣布第八代实例g8i的算力再升级,从SPR升级到EMR之后AI性能和整体性能均有显著提升。